网络上deepseek总是服务器繁忙,基于作者不太需要617B满血版参数(其实是没钱搞)。对于具有独立显卡的较新的笔记本,也是可以部署一下deepseek的。有时候它们或许能给我们也提供一些从未见过的视野和思考方式。
一、硬件配置
作者的笔记本硬件配置如下,想要部署个qwen-7b或llama-8b的版本就行,日常使用肯定是没问题的(因为作者试过了才写的文章)。
系统:Windows 11 家庭中文版
硬件:
- cpu:12th Gen Intel(R) Core(TM) i5-12450H 2.00 GHz
- 内存:24G
- 显卡:4060 8G
二、ollma下载安装和模型下载
使用ollama run命令进行下载,确实是有些不稳定的因素在,还是自行下载再导入吧。
ollama下载地址:https://ollama.com/
gguf模型下载:https://huggingface.co/lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF
三、ollama本地模型配置
我们在下载模型的同时就可以准备对应的Modelfile了
在模型的存放路径中,新增一个Modelfile,填入以下内容
FROM的值可以是已存在的模型,相对路径,绝对路径,按照自己需求选其中一种。
作者选择绝对路径这种方式,这样Modelfile放到哪个文件夹都可以,因为后面创建模型的时候可以指定modelfile的路径。
- FROM .\xxxxx.gguf 相对路径
- FROM D:\Users\xxxx\models\xxxxx.gguf 绝对路径
1 | FROM D:\Users\xxxx\models\DeepSeek-R1-Distill-Qwen-7B-GGUF.gguf |
三、创建模型
输入指令ollama create <模型名称> -f D:\Users\xxxx\models\Modelfile 就可以把模型导入Ollama了
1 | $ ollama create ds-qwen-7b-q4km -f D:\Users\xxxx\models\Modelfile |
最后出现success之后,我们输入ollama list检查模型列表
1 | $ ollama list |
四、运行并且利用插件进行联网功能
先载入模型,首次载入需要点时间,等载入之后就可以输入消息了。
1 | $ ollama run ds-qwen-7b-q4km |
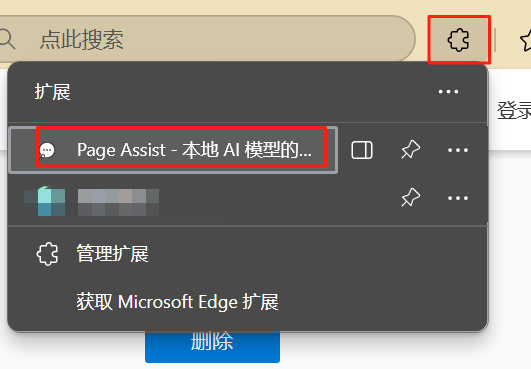
浏览器安装Page Assist - A Web UI for Local AI Models,edge浏览器和chrome都支持,它会检测你本地的ollama和运行中的模型
作者edge,安装地址:https://microsoftedge.microsoft.com/addons/detail/page-assist-a-web-ui-fo/ogkogooadflifpmmidmhjedogicnhooa?hl=zh-CN
安装完成后打开插件,选择模型,打开联网开关
提问了一句,你好,请问网络上对于deepseek的评价如何。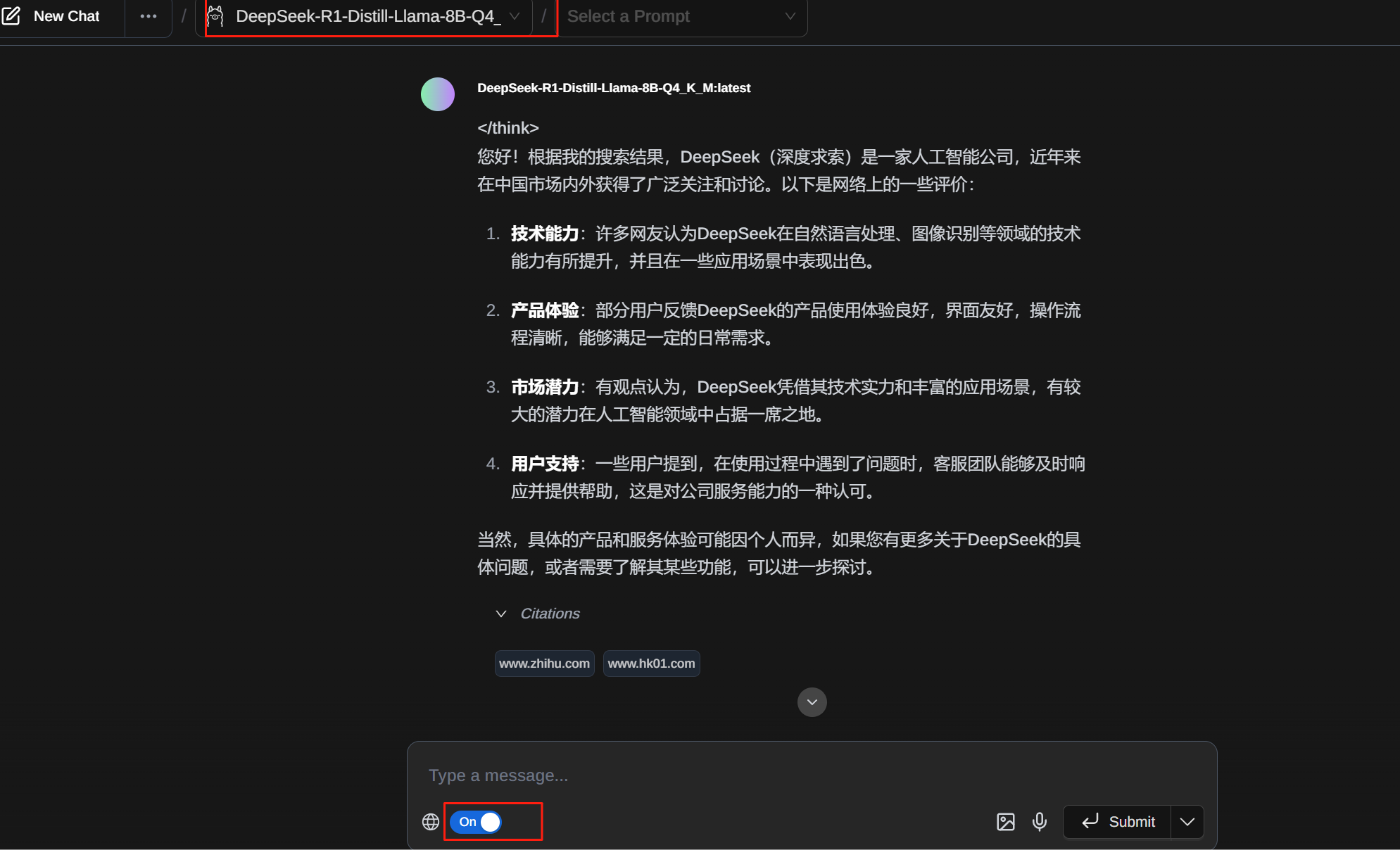
参考文章:
https://blog.csdn.net/weixin_46241866/article/details/144700025
https://github.com/ollama/ollama/blob/main/docs/modelfile.md#examples
https://www.bilibili.com/video/BV1LYA8eCESA/?spm_id_from=333.337.search-card.all.click&vd_source=aaf34ccf61cf5005766e1ee9255c16a5